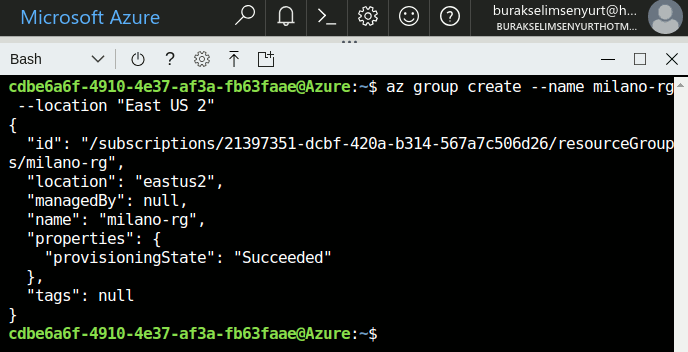
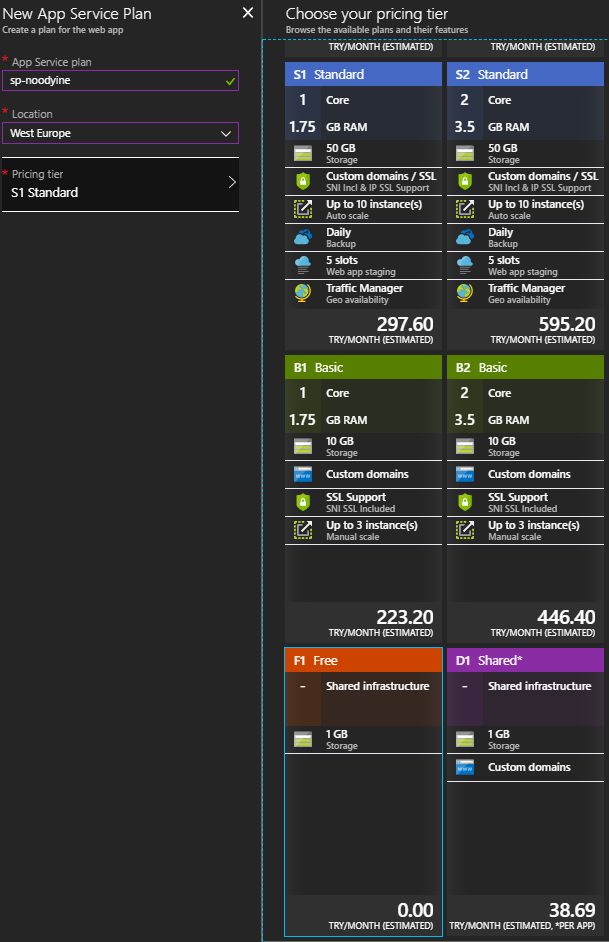
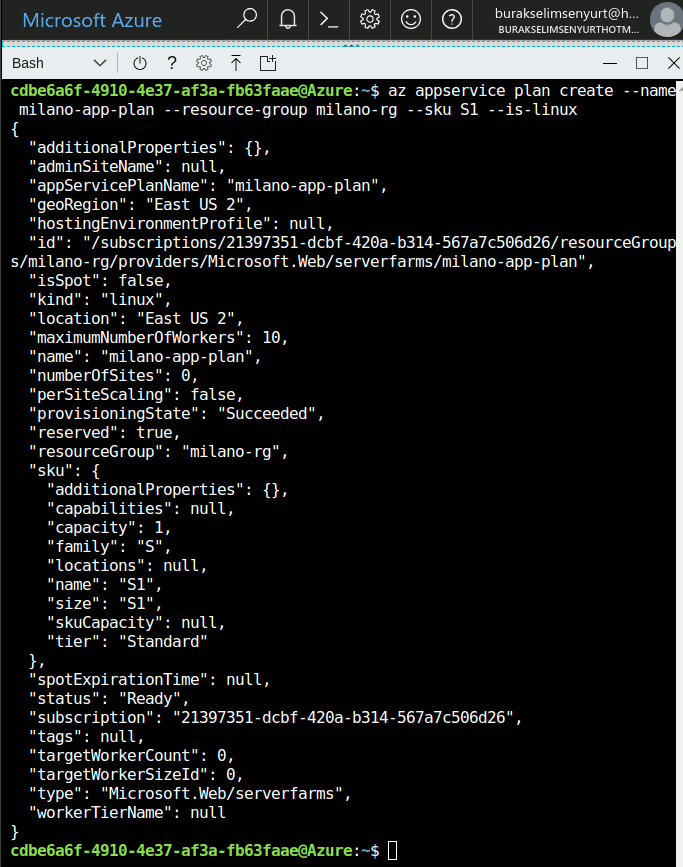
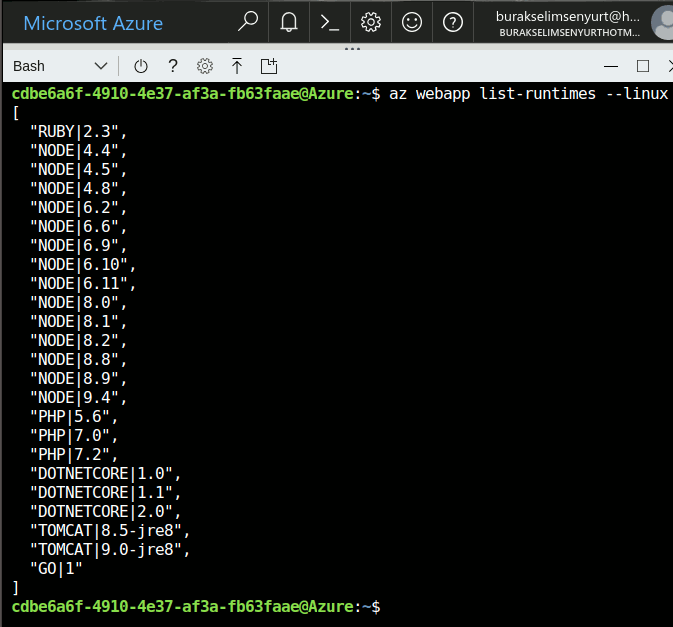
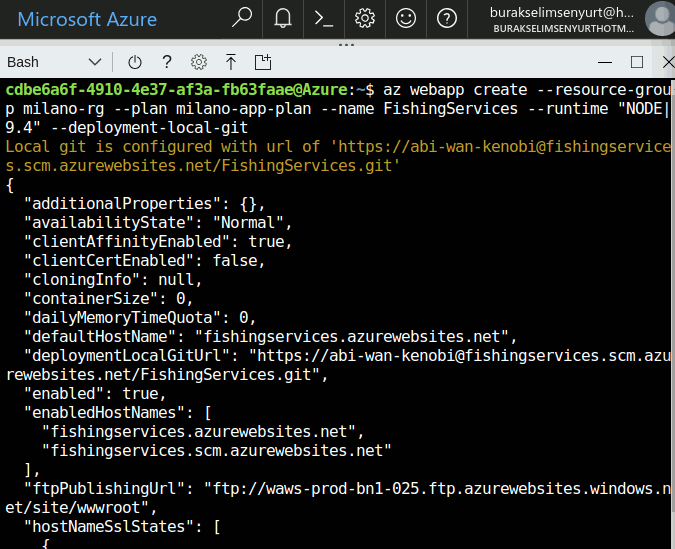
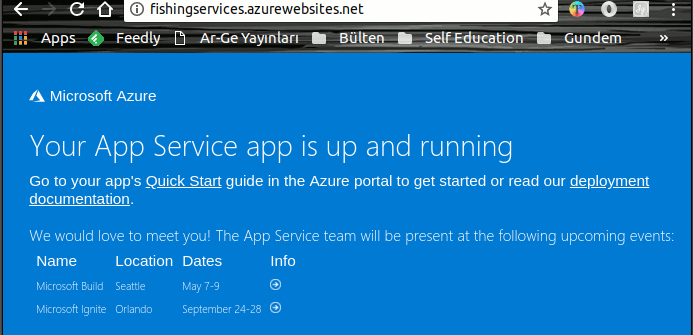
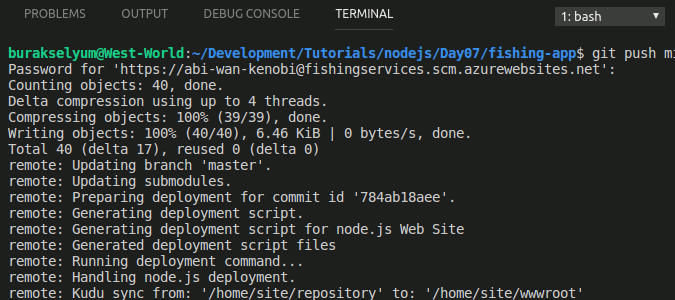
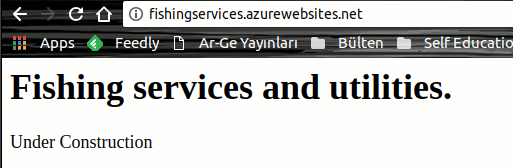
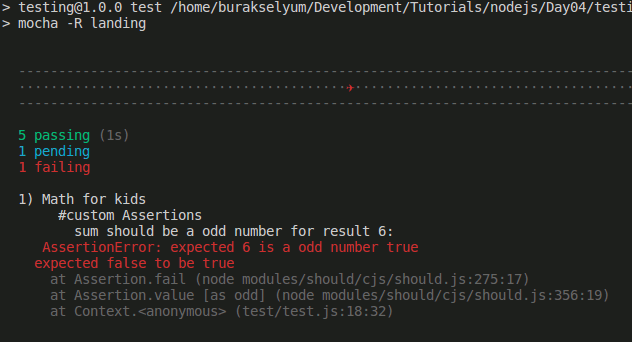
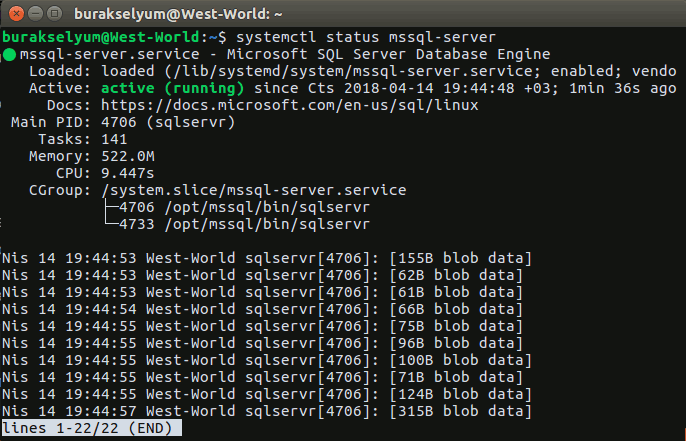
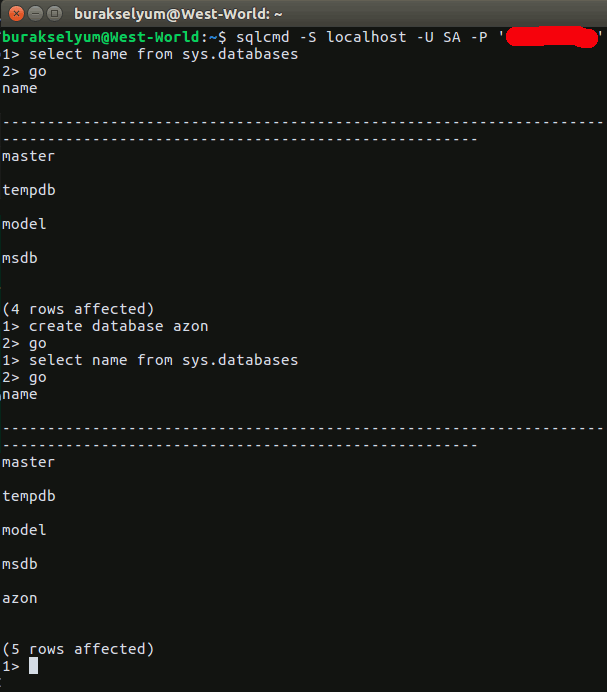
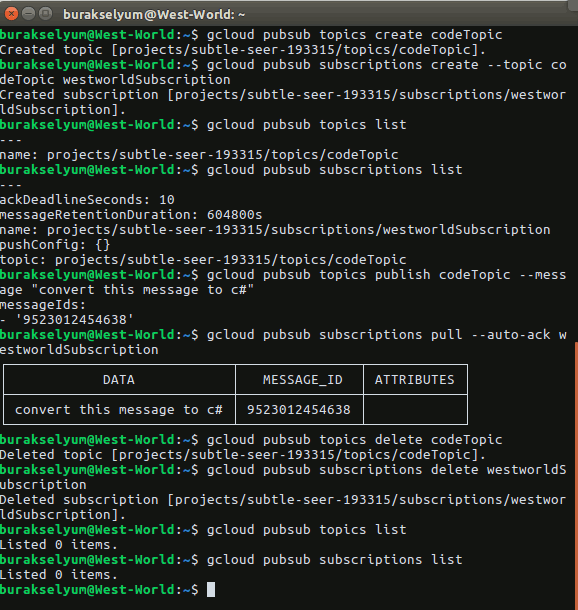
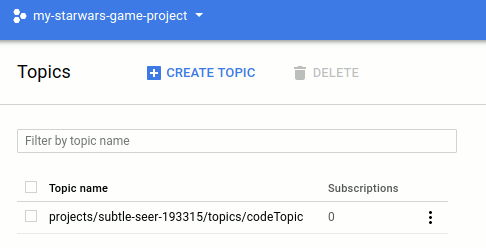
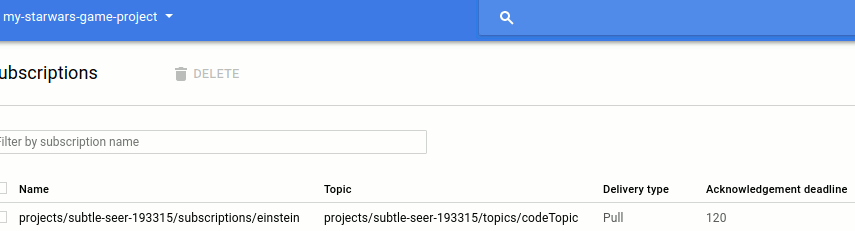
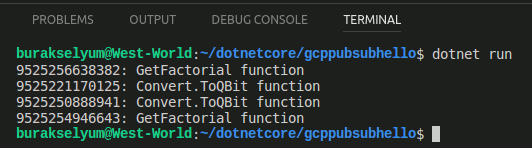
Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
Atlas denilince aklımıza gelen çoğunlukla coğrafya dersleridir. Hatta bu isimde coğrafya dergisi bile var. İşin köküne indiğimizde ise aslında bu ismin Yunan mitolojisinden geldiğini görmekteyiz. Yunan mitolojisine göre Atlas, Lapetos ve Klymene'nin 13 çocuğundan en güçlü olanıdır. Hatta o kadar güçlüdür ki Olympos'a saldırmış ve bu sebepten Zeus tarafından gök kubbeyi omuzlarından taşımakla cezalandırılmıştır. Hatta bu omuzlarda taşıma olayı bizleri o kadar etkilemiştir ki, kafatasını taşıyan ilk omura da tıp dünyası tarafından Atlas adı verilmiştir. Sanırım şimdi yandaki fotoğrafın ne anlama geldiğini daha net anladınız. Oysa ki Atlas'ın taşıdığı tek yük dünya ya da kafataslarımız değil. O, Big Data konusunda da büyük bir yükün altına girmiş durumda. İşte bugün inceleyeceğimiz konumuz. MongoDB'nin bulut çözümü hizmeti olan Atlas...
Atlas'a giriş mevzum yeni iş yerimdeki genç meslektaşlarım sayesinde gerçekleşti. Beni bu tip araştırmalara ittikleri için çok memnunum. Bir kaç gün öncesinde katıldıkları Hackathon'la ilgili izlenimlerini paylaşan arkadaşlarıma ne kadar teşekkür etsem azdır. Hemen nasıl bir şeydir araştırmaya başladım ve sonunda aşağıdaki çizimde yer alan senaryonun gerçekleştirilebileceğini öğrendim. Burada Node.js istemcisinin yerine farklı platformlar da gelebiliyor hemen söyleyeyim. Dilerseniz Ruby, Python gibi dilleri de katabilirsiniz. Ben son günlerin popüler konuşmaları özelinde Node.js tipinde bir istemciyi tercih ettim.
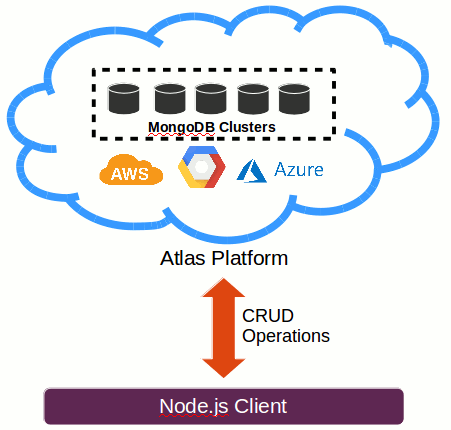
MongoDB aşina olduğumuz üzere oldukça başarılı ve popüler olan doküman bazlı NoSQL veritabanı sistemlerinden birisi. Atlas' da onun bulut tabanlı versiyonu olarak düşünülebilir. Bu şu anlama geliyor. Dilersek MongoDB veritabanımızı Cloud üzerinde konuşlandırabiliriz. Bu sayede sunucu ve yönetim maliyetlerini azaltmış, ölçeklenebilirlik gibi işleri de kolaylaştırmış oluruz. Atlas, esas itibariyle AWS, GCP ve Azure sunucu merkezlerini kullanmakta. Normalde bulut bilişim platformları kendi bünyelerinde çeşitli veritabanlarına hizmet sunarlarken Atlas bu işi belirli bir veritabanını ele alarak yapmakta desek sanırım yeridir. MongoDB kullanacağımız belli ancak hangi platform üzerinde konuşlandıracağımızı Atlas üzerinden şekillendirebiliyoruz.
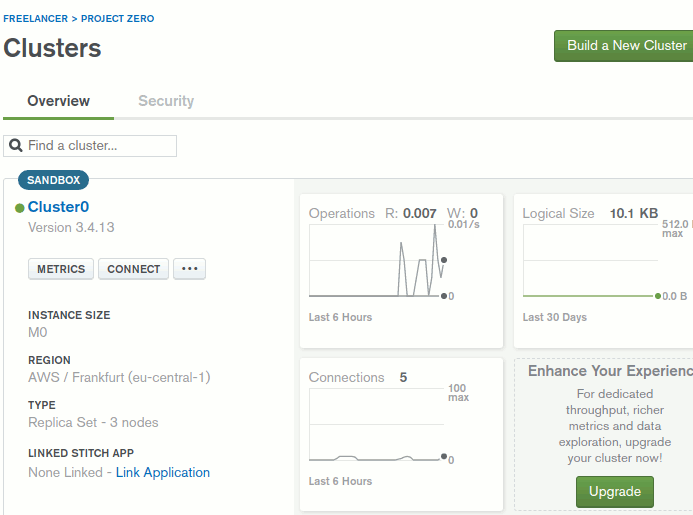
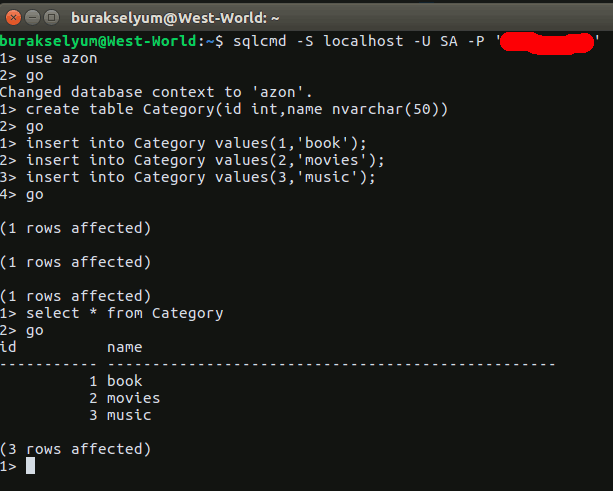
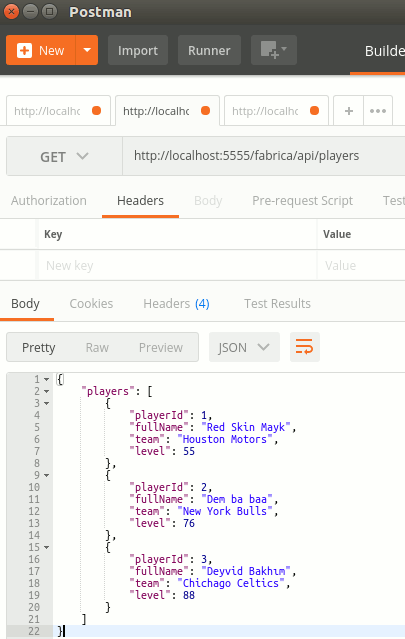
Ne demek istediğimi anlamanızın en güzel yolu şu adrese girip bir hesap açmakla olacak. Sonrasında bizi bekleyen şey proje açılması ve bir Cluster oluşturulması. Bu adımda kullanmak istediğiniz sunucu merkezini seçebiliyorsunuz. Ben 0$ maliyeti olan Free plan'ı seçerek Freelancer altında Project Zero isimli bir proje oluşturmakla işe başladım. Sandbox olarak geçen ürün içerisinde hemen varsayılan bir Cluster bir kaç dakika içerisinde oluşturuldu. Aşağıdaki ekran görüntüsünden görebileceğiniz üzere Frankfurt'ta ki AWS sunucularında 3 node'dan oluşan ve MongoDB'nin 3.4.13 sürümünü kullanan bir Cluster' ım var.
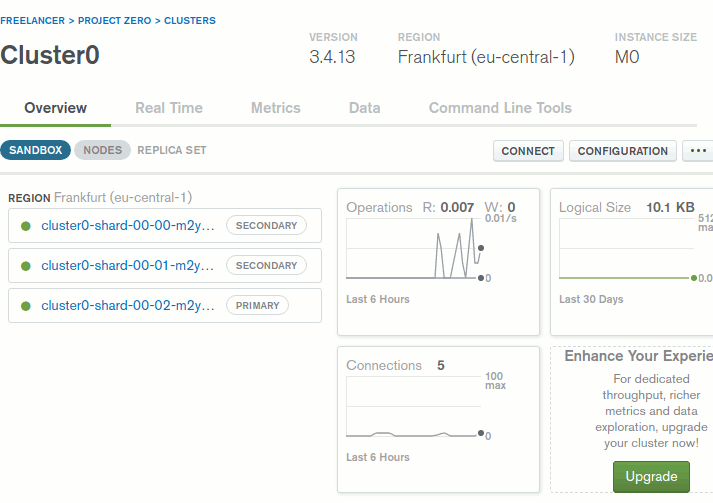
Projeyi seçip ilerledikten ve bazı basit operasyonları icra ettiktsen sonra Cluster içerisindeki node'lar da görebildim. İki secondary ve bir primary node söz konusuydu.
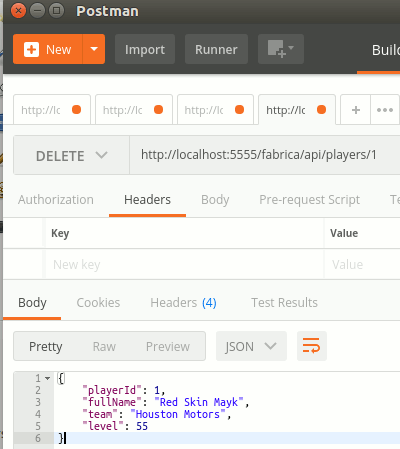
Benim amacım yazının başında da belirttiğimi üzere Atlas üzerinde oluşturacağım bir MongoDB örneğine, West-World'teki Node.js kodlarını kullanarak erişebilmek. Tabii bu tip bir iş için bazı ön gereklilikleri yerine getirmek lazım. Atlas üzerinde proje oluşturup Cluster yaratmak sadece bir başlangıçtı. Bunun dışında veritabanı ile ilişkili bir kullanıcının oluşturulması da gerekiyor. Ben örnek olarak scothy isimli bir kullanıcı oluşturdum ve bonkörlük edip ona DBAdmin rolünü verdim.
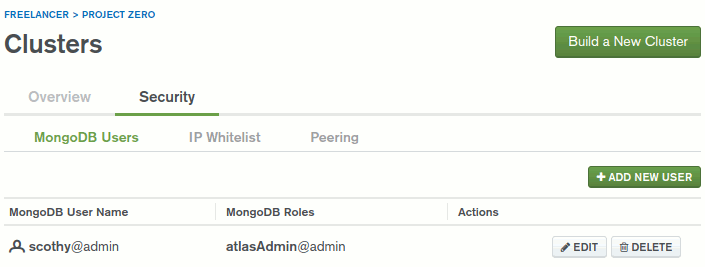
Kullanıcı oluşturmakta yeterli değil. Atlas üzerinde konuşlanacak olan MongoDB örneğine nereden erişilecek? Eğer herkesin kullanımına sunulacak bir veritabanı söz konusu ise Public erişim hakkı verebiliriz. Ben örnekten sadece kendi bilgisayarımdan erişim sağlanması için var olan o anki IP adresimi IP Whitelist adı verilen bölüme eklettim. Dolayısıyla veritabanına sadece West-World üzerinden erişilebilecek şekilde bir ayarlama yaptım. Tabii bu senaryo için işin can sıkıcı tarafı statik bir IP olmadığında yaşanıyor. Bu sebepten örnekleri hazırlarken zaman zaman güncel IP bilgisini yeniden eklemek durumunda kaldığım da oldu.
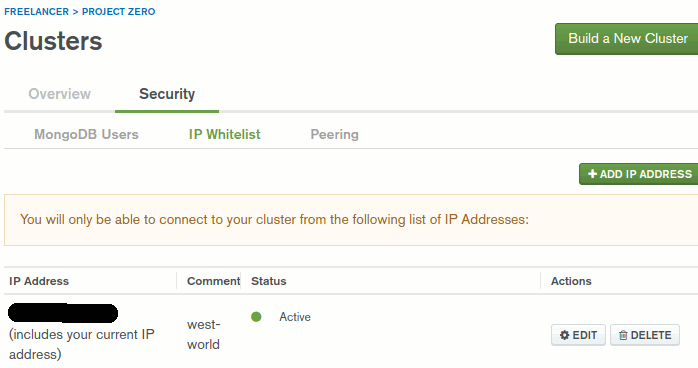
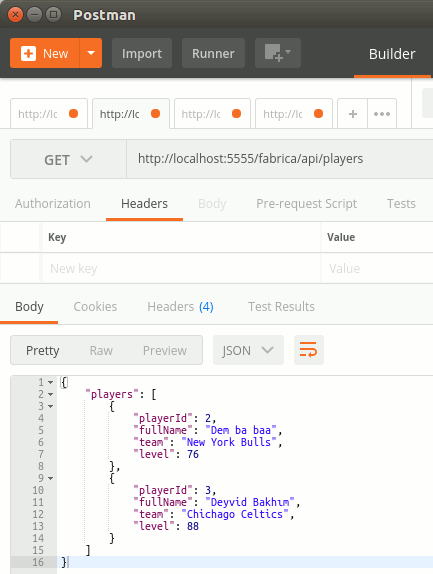
Bu adımları tamamladıktan sonra artık elimde Atlas üzerinde konuşlandırılmış bir MongoDB veritabanı olduğunu söyleyebilirim. Ama tabii ki bu da yeterli değil. Bir şekilde söz konusu veritabanına bilgi atabilmeli ve en azından bunu sorgulayabilmeliyim.
Atlas üzerindeki veritabanı ve içeriğine erişmek için bir kaç alternatif yol var. Kod tarafını denemeden önce MongoDB'nin Compass isimli ürününü kullandım. Aslında beni buraya götüren yol Atlas arabirimindeki Connect düğmesi oldu. Seçenekler arasında yer alan Compass'a bakmaya karar verdim(Bunun dışında uygulama ve Shell seçenekleri de bulunuyor)Öncelikle West-World'ün Ubuntu 64bit versiyonu için gerekli deb uzantılı paketi belirtilen adresten indirdim. Kurulum işini gerçekleştirmek işin en basit kısmıydı.
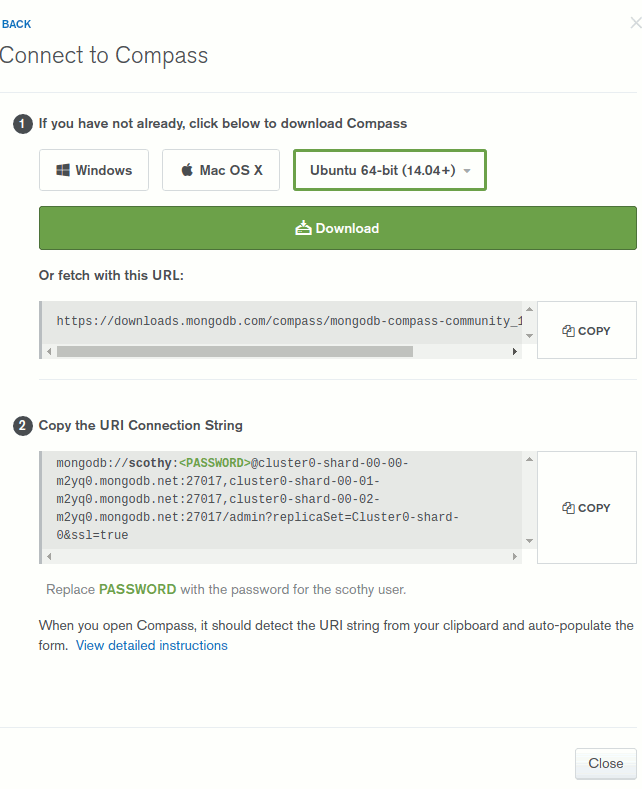
Bu arada fotoğrafın altındaki bilgiye de dikkatinizi çekerim.
Tahmin edeceğiniz gibi sonrasında Atlas'a bağlanmak gerekiyor. Atlas şu an için West-World'ün oldukça uzağında taaaa Frankfurt'ta ikamet ediyor. Bu nedenle bağlantı bilgileri de önemli. Yukarıdaki ekran görüntüsünde bir de ConnectionString bilgisi olduğunu fark etmişsinizdir. Bu bilgiyi panoya kopyalamak aslında yeterli. Compass'i açtığımızda otomatik olarak host, port, username, gibi bilgiler doldurulmakta. Ama dolmayabilir de. Ki ben denemelerimi yaparken eksik olarak eklendiler. Temel olarak aşağıdaki ekran görüntüsünde yer alan bilgilerin doldurulması gerekiyor. Buradaki Hostname, Replica Set Name bilgileri önemli. Port aksi belirtilmedikçe 27017 olarak veriliyor. Authentication modunda kullanıcı adı ve şifre kullanacağımızı belirtmemiz lazım. Bu, Atlas üzerinde oluşturduğumuz kullanıcının bilgileri.
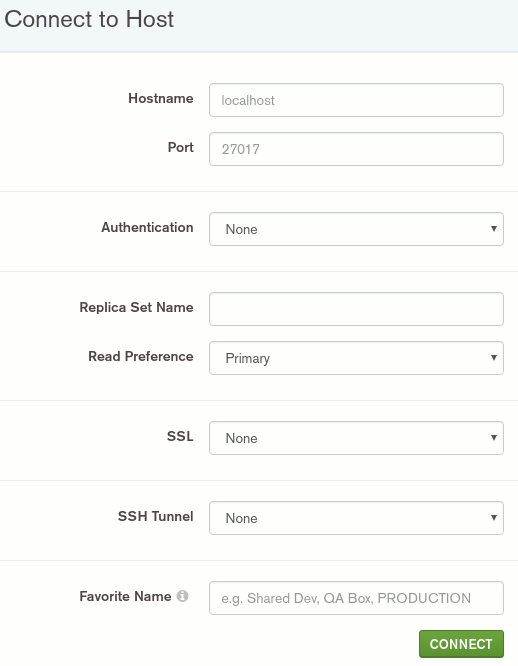
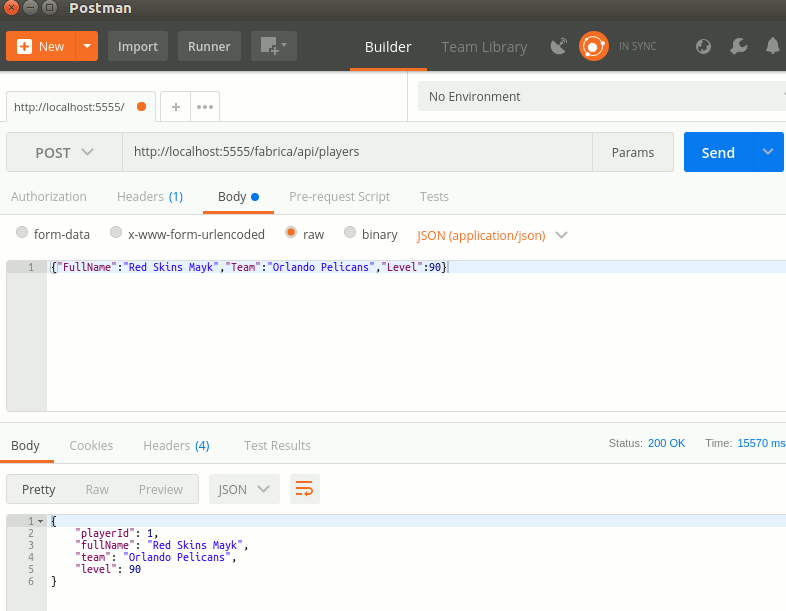
Ben bu bilgileri doldurduktan sonra Project Zero'da yer alan Cluster0'a bağlanmayı başarabildim. Sonrasında ilk işim remote isimli bir veritabanı oluşturmak ve içerisine gamers isimli bir koleksiyon(collection) koymak oldu. Hatta aşağıdaki JSON içeriğini alıp,
{
"primary_info": {
"weapon": "lazer cannon",
"motto": "go go gooo",
"movie": "star wars - Jedi the last"
},
"max_point": 385,
"min_point": 35,
"matches": [
{ "game_day": 1, "vs": "lord rikken", "player_score": 200, "opponent_score":145 },
{ "game_day": 2, "vs": "evelyn", "player_score": 189, "opponent_score":485 },
{ "game_day": 3, "vs": "moka pinku", "player_score": 21, "opponent_score":18 },
{ "game_day": 4, "vs": "draymmeor", "player_score": 53, "opponent_score":56 }
],
"current_rank":3,
"nickname": "lord fungus mungus",
"player_id": "21454834"
}gamers koleksiyonuna yeni bir doküman olarak da ekledim. Sonuç şöyleydi...
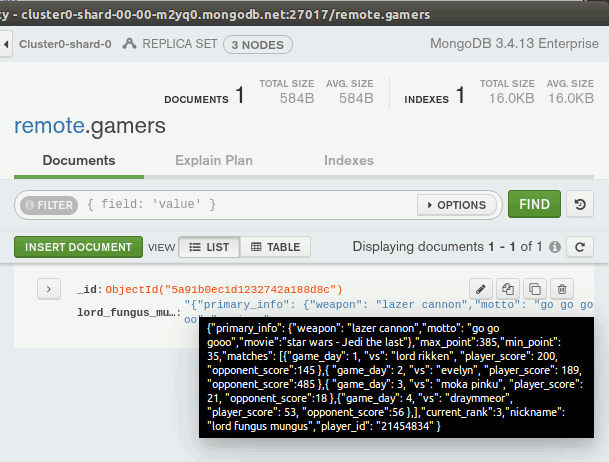
Pek tabii hedefim bir kod parçasından faydalanarak Atlas ile haberleşmekti. Hali hazırda basit bir veri içeriği de eklediğime göre en azından Atlas'a bağlanıp bu içeriği çekmeyi deneyebilirdim. Pek çok programlama ortamı için yardımcı paketler mevcut. Ben son ay içerisinde haşırneşir olduğum Node.js tarafında ilerlemek istedim. Bu nedenle West-World'de Visual Studio Code'u kullanarak aşağıdaki kodları içeren basit bir js dosyasyı hazırladım.
var MongoClient = require('mongodb').MongoClient;
function getAllGamers(url) {
console.log("processing...");
return new Promise(function (resolve, reject) {
console.log("connecting...");
MongoClient.connect(url, function (err, db) {
var dbo = db.db("remote");
var query = {};
console.log("fetching...");
dbo.collection("gamers")
.find(query)
.toArray(function (err, result) {
if (err) {
reject(err);
} else {
console.log("we have gamers now...")
resolve(result)
}
db.close();
});
});
})
};
function main() {
url = "mongodb://scothy:tiGeR@cluster0-shard-00-00-m2yq0.mongodb.net:27017/admin?replicaSet=Cluster0-shard-0&ssl=true"
getAllGamers(url).then(function (result) {
console.log(result);
}, function (err) {
console.log(err);
});
console.log("mongodb examples...")
};
main();İlerlemeden önce kodda neler olup bitttiğini anlatsam iyi olacak. Temel olarak iki fonksiyonumuz bulunuyor. main ve getAllGamers. getAllGamers Atlas üzerinde konuşlandırdığımız koleksiyonun tüm içeriğini sorgulamak için kullanılmakta(Select * from'un hallicesinden) Tabii node.js'in npm paketini kullandığımızı da fark etmişsinizdir. Bu da
npm install mongodb
terminal komutunun gerekli olabileceği anlamına geliyor. connect fonksiyonu içerisindeki ilgili metodlarla, remote veritabanındaki gamers koleksiyonuna kadar gidiyor ve tüm içeriği bir array'e alıyoruz. Tabii kod tarafında dikkatinizi çeken bir şey de olmuştur. getAllGamers içerisinde promise isimli bir nesne örneği döndürülmekte. Bu benim yeni duyduğum ve henüz idrak etmeye çalıştığım farklı bir asenkron uygulama yaklaşımı. Normalde node.js asenkron çalışma prensiplerini benimsiyor ancak callback tarzı kullanımların bir takım sıkıntıları olduğu dillendirilmekte. Callback fonksiyonunun hiç çağırılmaması, az ya da çok çağırılması, parametrelerinin doğru alınamaması, hataların kaybolması gibi sorunlardan bahsedilmekte. Promise adı verilen yapıda ise belli başlı avantajlar var. Örneğin istenilen görev tamamlandığında promise değişikliğe uğramıyor. Immutable bir tip olduğunu ve kararlı bir nesne yapısı bahşettiğini anlayabiliriz. İşlem sonucu sadece bir kereliğine başarıya ulaşabilir veya ulaşamaz. Bu, resolved ve rejected durumları ile ele alınmakta. Öngörülemeyen hatalarda promise otomatikman rejected moduna geçiyor.
Koddan da fark edeceğiniz üzere toArray fonksiyonunun parametresindeki isimsiz metodda reject ve resolve çağrıları söz konusu. Veri sonucu alındığında tetiklenen resolve fonksiyonu sonucun getAllGamers.then metodundan ele alınabiliyor olmasını sağlamakta. Tabii bir hata olması halinde reject operasyonunun tetikleneceği de aşikar. Biraz kafa karıştırıcı değil mi? En azından benim için öyle. Oysaki promise kullanımını hamburger siparişi ve siparişin hazır olması sonrası çalan masa zili ile gayet güzel bir tasvirleyerek anlatan esaslı bir yazı var. Özgün Bal'ın şu yazısını mutlaka okumanızıöneririm.
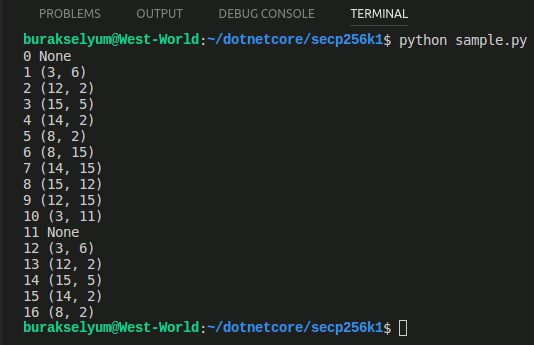
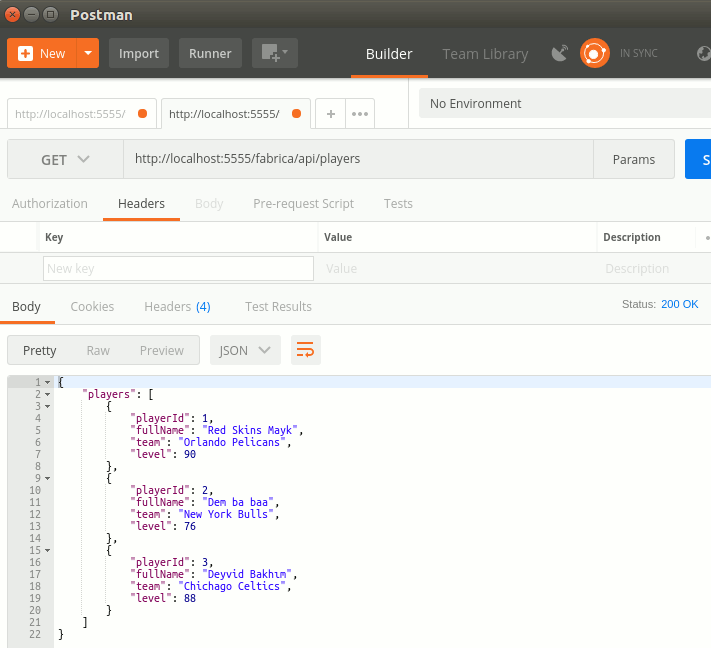
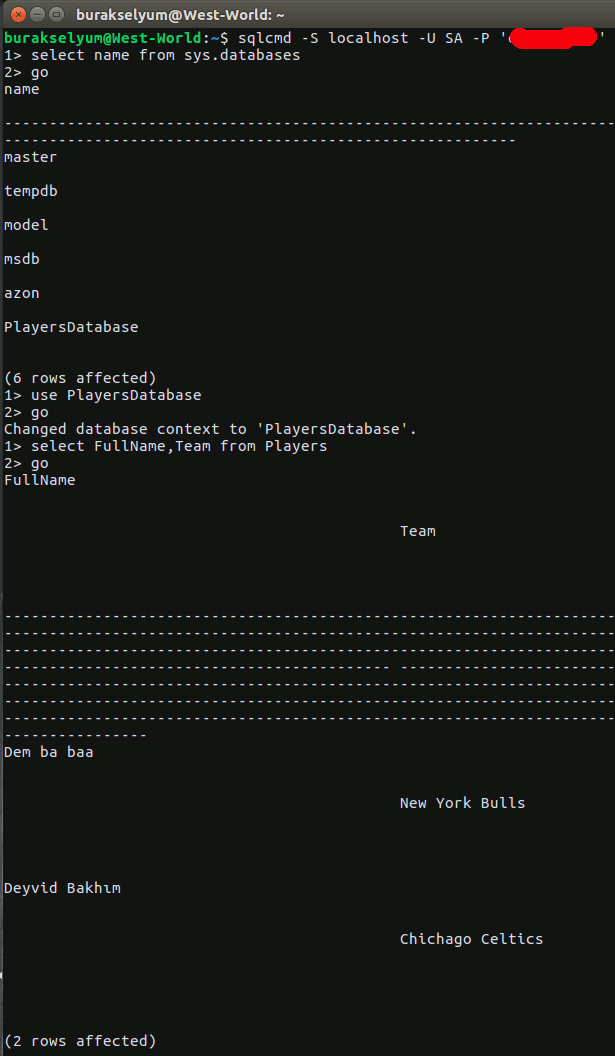
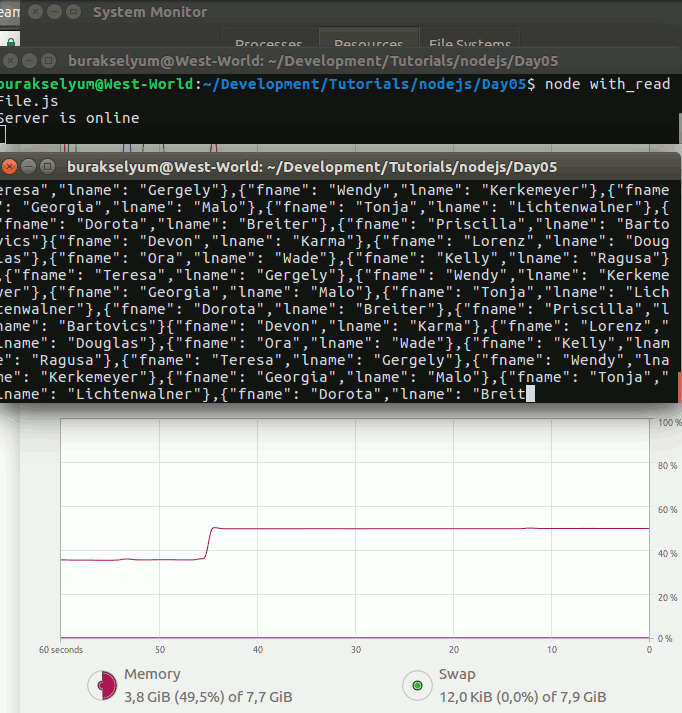
Sonuçta uygulamayı çalıştırdığımda gamers koleksiyonunun içeriğini çekebildiğimi fark ettim.
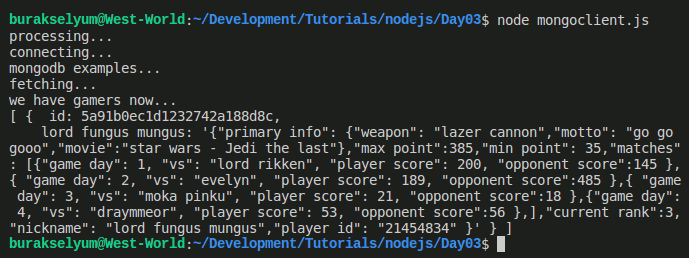
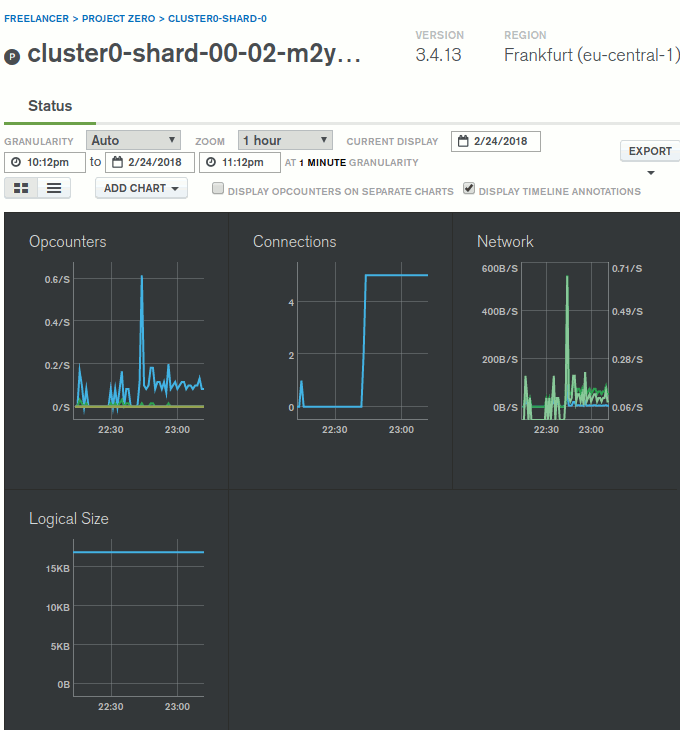
Tüm bu işlemler olurken Atlas üzerinde de veri hareketlilikleri olmakta tabii ki. Onları izlemek mümkün, sonuçlara göre ölçeklendirme ile ilgili bir takım yönetimsel işlemleri yapmak mümkün. Eğer kullanılan cluster'lara bakılırsa aşağıdaki ekran görüntüsünde olduğu gibi gayet güzel grafikler sunuluyor.
Bu güzel gelişmelerden sonra kod tarafını biraz daha kurcalamak istedim. İlk olarak yeni bir koleksiyonu nasıl oluşturabilirim buna baktım. Promise konusunu şimdilik işe katmadan(ki kullanımına alışana kadar kafamı karıştırsın istemiyorum) koda aşağıdaki createCollection fonksiyonunu ekledim.
function createCollection(url, name) {
console.log("db create process...");
MongoClient.connect(url, function (err, db) {
if (err) throw err;
var dbOwner = db.db("remote");
dbOwner.createCollection(name, function (err, res) {
if (err) throw err;
console.log("collection created!");
db.close();
});
});
};url ve name isimli iki parametre alan createCollection fonksiyonu MongoClient.connect ile Atlas'a bağlantı sağladıktan sonra üzerinde işlem yapabilmek için remote veritabanını işaret eden bir db nesnesi örnekliyor. Sonrasında dbOwner isimli nesne örneği üzerinden createCollection metodu yardımıyla ilgili koleksiyonun oluşturulması sağlanıyor. Kodun main fonksiyonu içeriği ise şu şekilde.
function main() {
url = "mongodb://scothy:tiGeR@cluster0-shard-00-00-m2yq0.mongodb.net:27017/admin?replicaSet=Cluster0-shard-0&ssl=true"
createCollection(url,"designers");
console.log("mongodb examples...")
};
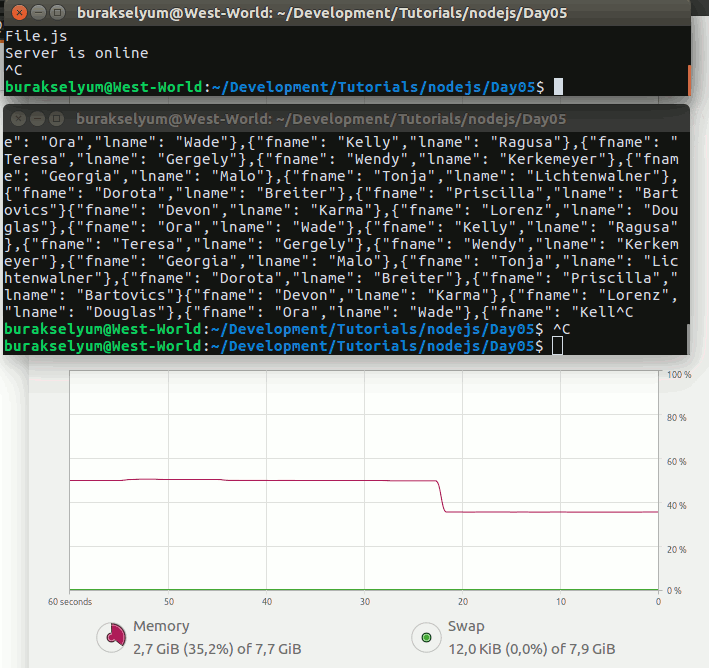
main();Çalışma zamanı çıktısı tam da istediğim gibiydi. gamers dışında designers isimli yeni bir koleksiyon daha oluşmuştu.
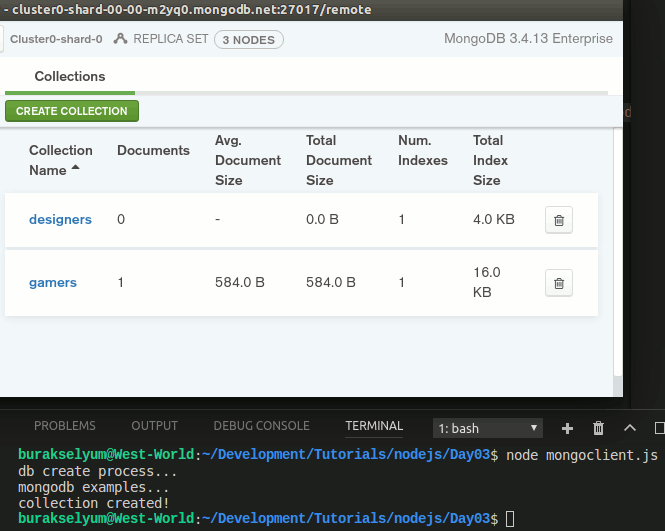
E o zaman birde bu yeni koleksiyona doküman eklemeyi denesek mi? İşte bu işi üstlenecek insertDesigner isimli fonksiyonumuz.
function insertDesigner(url,content){
console.log("inserting...");
MongoClient.connect(url,function(err,db){
if(err) throw err;
var dbOwner=db.db("remote");
dbOwner.collection("designers").insertOne(content,function(err,res){
if(err)throw err;
console.log("a new designer inserted");
console.log("ID : %s",res.insertedId);
db.close();
});
});
};
function main() {
url = "mongodb://scothy:tiGeR@cluster0-shard-00-00-m2yq0.mongodb.net:27017/admin?replicaSet=Cluster0-shard-0&ssl=true"
var vanDyk={fullName:"Yurri van dayk de la rossa",country:"green age",system:"Tatuin",expLevel:980};
insertDesigner(url,vanDyk);
console.log("mongodb examples...")
};
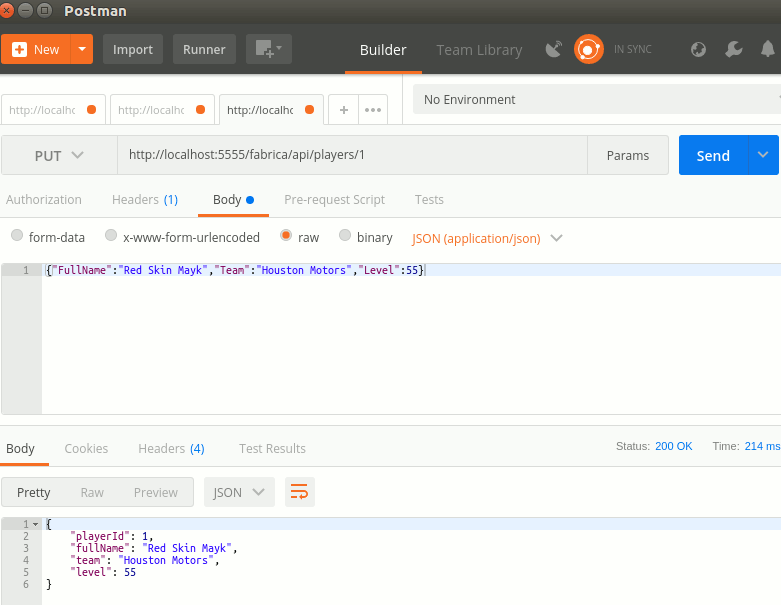
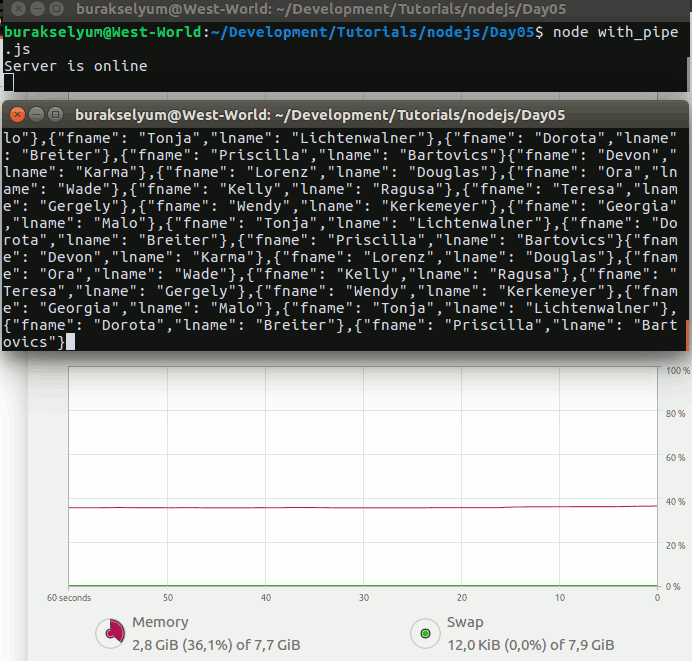
main();Bu sefer collection fonksiyonu ile yakaladığımız koleksiyon için insertOne metodu yardımıyla yeni bir JSON nesnesini göndermekteyiz. Kodun West-World tarafındaki çalışma zamanı sonuçları aşağıdaki gibi.
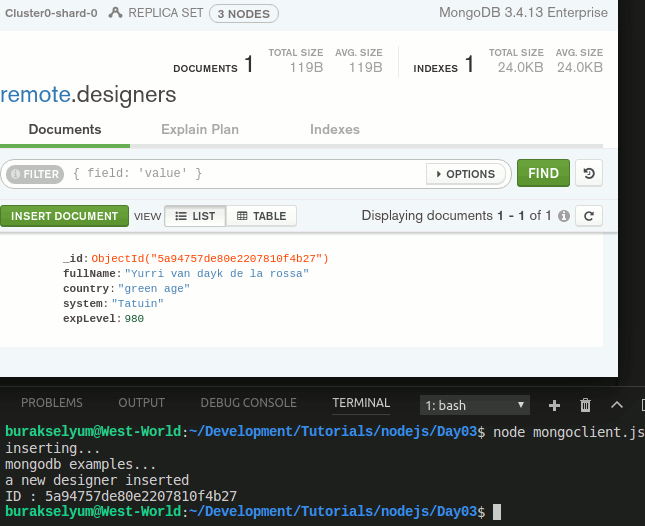
Dikkat edileceği üzere insertOne metodunun ikinci parametresi olarak kullanılan fonksiyondaki res değişkeni üzerinden, henüz eklenen dokümanın MongoDB tarafında üretilen objectId bilgisine ulaşabildik.
Örnekte yer alan insertOne metodu dışında kullanabileceğimiz bir diğer alternatif de insertMany. Adından da anlaşılacağı üzere koleksiyona birden fazla doküman eklemek istediğimiz durumlarda kullanılabilir. remote veritabanındaki designers koleksiyonu için ben şöyle bir deneme yaptım.
function insertDesigners(url,content){
console.log("inserting...");
MongoClient.connect(url,function(err,db){
if(err) throw err;
var dbOwner=db.db("remote");
dbOwner.collection("designers").insertMany(content,function(err,res){
if(err)throw err;
console.log("%i documents inserted",res.insertedCount);
db.close();
});
});
};
function main() {
url = "mongodb://scothy:tiGeR@cluster0-shard-00-00-m2yq0.mongodb.net:27017/admin?replicaSet=Cluster0-shard-0&ssl=true"
var designers=[
{fullName:"blue man",country:"ingland",system:"oceanic continent",expLevel:256},
{fullName:"Reddick",country:"red sun",system:"world",expLevel:128},
{fullName:"mari dö marş",country:"pari",system:"moon",expLevel:45}
];
insertDesigners(url,designers);
console.log("mongodb examples...")
};
main();Bu sefer bir JSON nesne dizisini parametre olarak kullanmaktayız. Her birisi ayrı birer doküman olarak değerlendirilecek. İşte benim elde ettiğim sonuçlar,
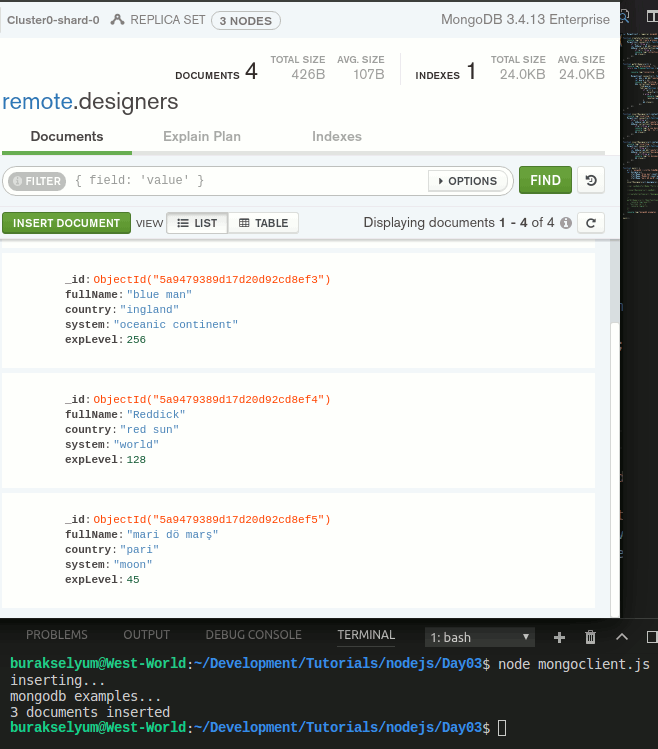
Örnekler çoğaltılabilir. Doküman sorgulanması, veritabanı üretilmesi, çeşitli kriterlere göre sorgulamalar yapılması gibi temel pek çok operasyon kolaylıkla gerçekleştirilebilir. Söz konusu kodlar birer WebAPI servisi gibi tasarlanabilir de. Siz görevinizi anladınız değil mi?
Eğer konusunda veri kullanılması gereken bir startup denemesi veya bir proje ya da tez ödevi olsa sanırım Atlas gibi platformların Free Plan statüsündeki versiyonlarını kullanmayı tercih edebiliriz. Maliyeti sadece internet ücreti ile sınırlı olacaktır. Üstelik istemci tarafını geliştirmekte oldukça basit. Senaryolar çokça çeşitlendirilebilir. Node.js uygulamasının yine bulut üzerinde bir yerlde servisleştirilmesi ve bu servisin Atlas ile konuşarak MongoDB tabanlı veri yapılarını kullanması pekala mümkün. Günümüzde birbirine bağlanamayan sistem neredeyse kalmadı gibi ne dersiniz :) Böylece geldik bir makalemizin daha sonuna. Tekrardan görüşünceye dek hepinize mutlu günler dilerim.
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,

 Merhaba Arkadaşlar,
Merhaba Arkadaşlar, ,
,

 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,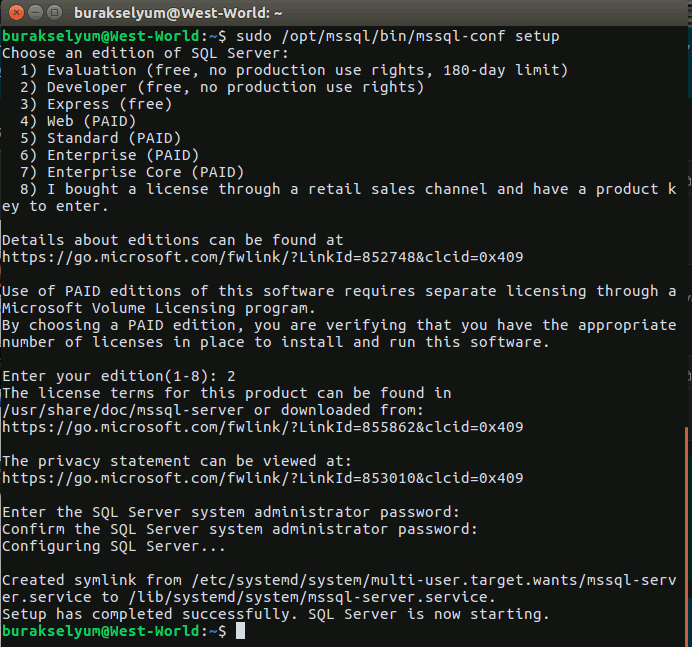
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,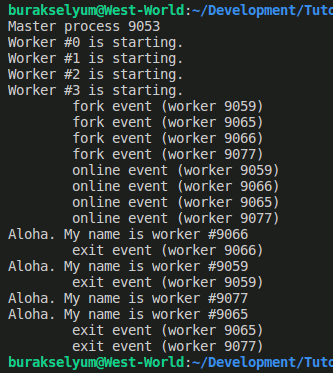
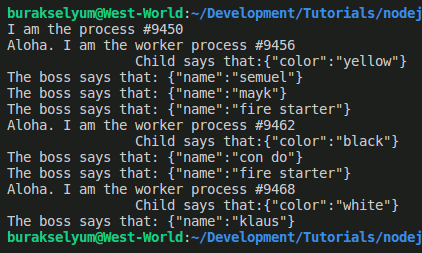
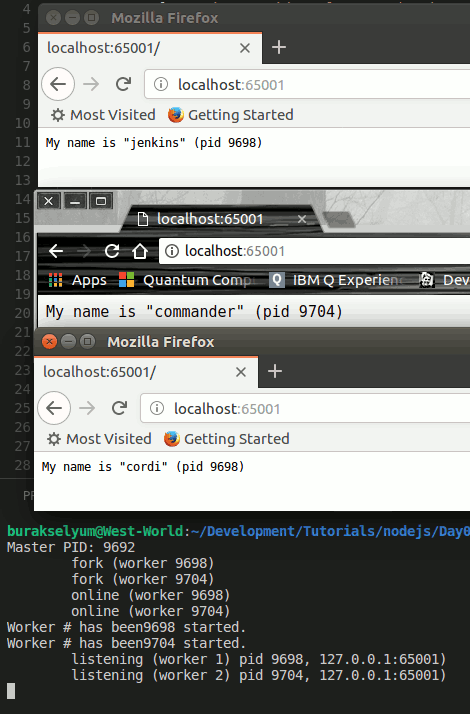
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,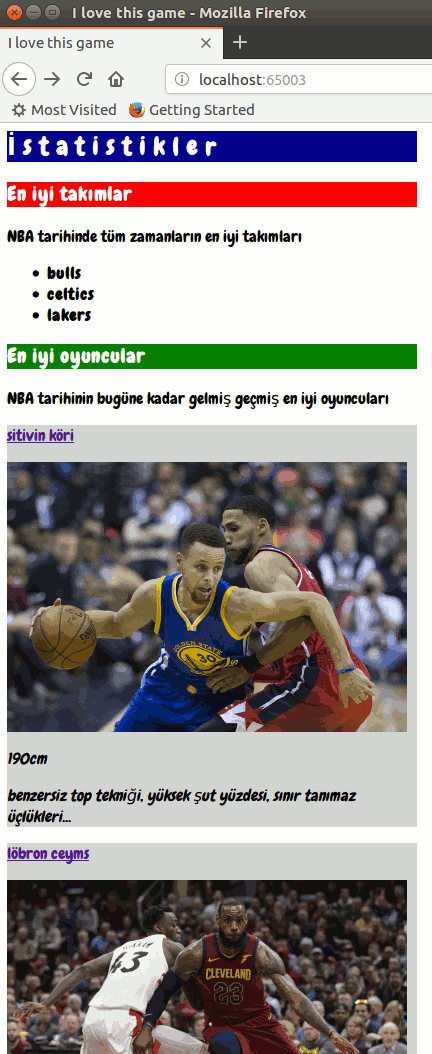
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,

 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,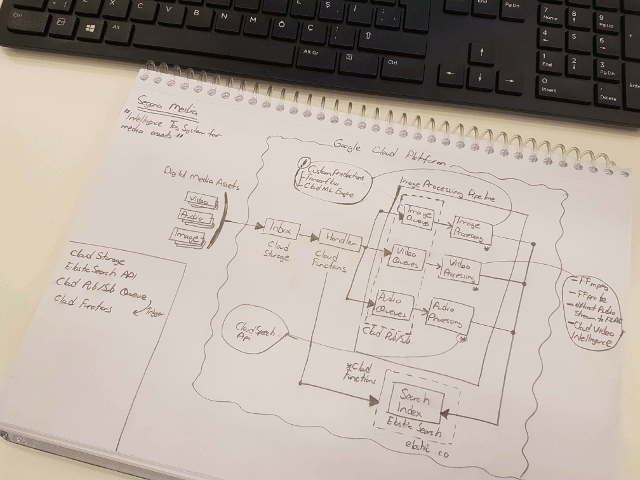


 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,